中文
中文



Computer programs that are able to move across the network, replicate themselves, infiltrate personal computers and IT infrastructure and cause untold damage to enterprises have been present since the 1970s and '80s. The increased cyber threat activity during these two decades led to an explosion of cybersecurity solutions in the '90s, primarily focused on detecting harmful software in IT systems.
In the last five years, modern cyberattacks have used highly sophisticated techiques to bypass an organization’s cyberdefenses. Moreover, since the beginning of the COVID-19 pandemic, there has been a dramatic increase of cyber attacks in various organizations. Based on recent studies, the likelihood to experience a data breach of at least 10,000 records is close to 30% (Security Intelligence study), and it takes nearly 10 months to identify and contain data breaches, where the average data breach in the U.S. costs about $8.2 million.[1]
There are different types of cyber attacks based on how they attack a system and which system components they target, as shown in Figure 1. More specifically, some sample threat categories are:
- Information Gathering: Information about the IT infrastructure is collected based on sniffing and scanning network ports, in-server traffic, and running processes. This is normally one of the first steps taken by the hackers in order to understand IT systems
- Intrusions: The bad actor gains access into the organization’s computer system. A use case in hits category is account takeover (ATO), which takes place when a user account is compromised
- Fraud: Attackers pretend (“masquerading”) to be reputable entities in order to induce revelation of sensitive information
- Malware: Malicious software (viruses) that are designed to cause harm or gain unauthorized access
- Availability Attacks: These are brute force attacks (e.g., denial of service, DoS) that attempt to break down system integrity and reliability by sending a large number of malformed requests
Figure 1. Machine learning approach to cyber threats
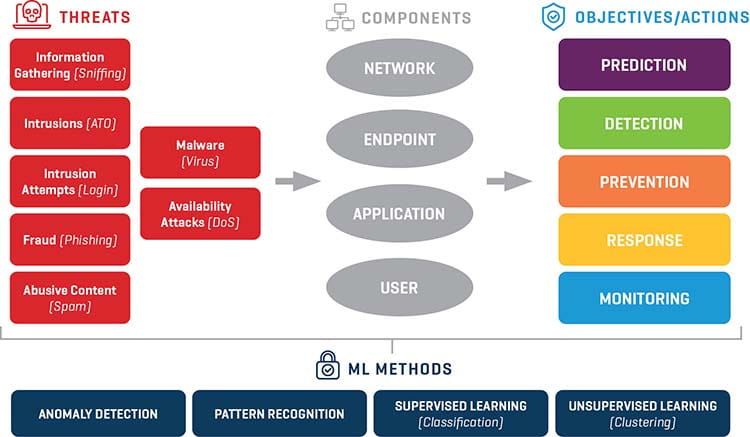
Cyber threats attack one (or more) system components out of the four main ones:
- Network
- Endpoints: the end-user devices, such as laptops and mobile devices
- Applications
- Users
In order to protect these four system components, the cybersecurity framework used needs to ensure that the tasks of threat prediction, detection, prevention, and monitoring are implemented correctly.
Why Machine Learning and AI
Traditional cybersecurity detection methods are based on matching attack “signatures” with system input data (Figure 2). These signatures are the digital fingerprints of threats that have been identified in the past, and they are represented as unique sets of binary data or hashes (numbers derived from strings).
Figure 2. Machine Learning vs. traditional methods in cybersecurity
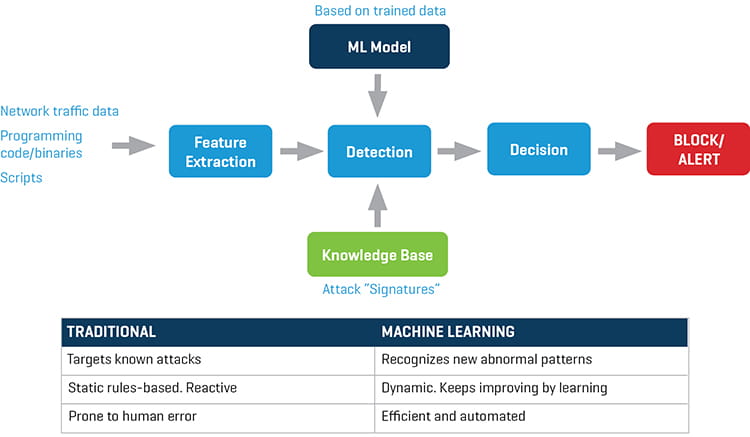
As shown in Figure 2, the cybersecurity detection engine receives all relevant input data, such as network traffic data or application binaries. After it extracts the features it needs (e.g., IP addresses from network data), it detects a threat by matching input data with known signatures. However, this matching process is static and reactive to threats, and attacks are detected long after the system was compromised. By integrating machine learning methods and artificial intelligence into the cyber defense engine, the threat detection process becomes dynamic and able to detect unknown threats based on past learnings. Moreover, well-established artificial intelligence (AI) algorithms used for anomaly detection and pattern recognition are leveraged.
Machine learning algorithms learn from training data, and when these data are labeled (supervised learning) the prediction accuracy is higher. However, in real life, finding these labeled data sets is the main challenge. In some cases, publicly available labeled data sets are used. Alternatively, past, unlabeled data from the IT systems are used, and unsupervised methods are applied. In this scenario, the AI algorithms cluster the data into several categories based on similarities in the data fields. For example, several clusters will be discovered in the training phase, where one cluster aggregates data that signify malware, another cluster aggregates IP spoofing data, and a third one contains all “non-threat-related” data points. K-means clustering is a very common clustering method, where a measure of distance (assuming numerical data) among input data fields is used to define similarity.
Case study: ML/AI Use in Network Breaches
The Open Systems Interconnect (OSI) Reference model designed by the International Standard Organization (ISO) describes network activities as having a structure of seven layers. However, the modern Internet network architecture follows the TCP/IP protocol, which condenses OSI’s seven layers to five.
Threat attacks can be launched against all five layers:
- Physical Layer (e.g., Ethernet/IEEE 802.3): Jamming attacks
- Data Link Layer (e.g., PPP): 802.1X attacks
- Network Layer (e.g., IP): IP address attacks, VPN cache attacks
- Transport Layer (e.g., TCP, UDP): sequence number prediction, SYN flooding
- Application Layer (e.g., DNS, FTP): SQL injection, DNS poisoning, Flash and pdf obfuscations
Figure 3 below shows a simplistic, high-level network architecture where an intrusion detection/prevention system (IDS/IPS) is positioned behind the main firewall and before the demilitarized zone (DMZ). Without going into a lot of details, the objective of the IDS filters is to create alerts on suspicious activity, while the IPS filters are used for automatic blocking traffic or quarantining an endpoint.
Figure 3. Placement of IDS/IPS in an enterprise network

The goal here is to detect and prevent all anomalies captured by analyzing network traffic. Therefore, rules are used for anomaly detection; the methods that are used to generate these rules are very important in how accurate the overall system is. There are three main methods for defining these rules:
- Knowledge-/Expert-based rules: The rules are captured from human expert knowledge, protocol specifications and potential network traffic instances. For example, a human expert derives the rules for certain protocols, such as IP or TCP. When data show anomalies, such as IP defragmentation overlaps or illegal TCP options and usage a red flag is raised.
- Statistical-based methods: Stochastic methods are used to describe network traffic and statistical approaches such as multivariate or time series models are leveraged. The objective is to calculate the normal range of network metrics and parameters because all activity outside these ranges is deemed as harmful. However, calculating thresholds for normal network operations is a very difficult task, balancing false positives and false negatives produced by the stochastic approaches.
- Machine Learning-based methods: This approach is different than the statistical one because it identifies which characteristics are needed to build a model of network behaviors based on learning from past data. Unsupervised anomaly detection is widely applicable due to absence of labeled data. If models are generated correctly, it provides the most accurate and dynamically generated rules.
Machine Learning as a Necessary Tool in Cybersecurity
Malicious actors started deploying AI-based and bot-driven cyber attacks in the last few years. As a result, conventional cyber defense methods are not sophisticated enough to capture new threats and protect IT systems. Carefully designed and tested machine learning methods have to be deployed in order to adaptively match the complexity of new cyber attacks.
Stout’s digital practice has the expertise in the areas of AI and cybersecurity and can assess IT systems and provide detailed reports and practical insights and recommendations on which statistical and/or AI-based methods need to be applied in order to prevent future cyber attacks.
- Cost of a Data Breach Report 2020, Ponemon/IBM, 2019.